编写一个猥琐的反爬虫系统是怎样一种体验

http://techshow.ctrip.com/campus/
为什么要反爬虫
- 爬虫占总PV比例较高,这样浪费钱(尤其是三月份爬虫)。
- 公司可免费查询的资源被批量抓走, 丧失竞争力, 这样少赚钱。
- 爬虫是否涉嫌违法? 如果是的话, 是否可以起诉要求赔偿? 这样可以赚钱。
反什么样的爬虫
- 十分低级的应届毕业生
- 十分低级的创业小公司
- 不小心写错了没人去停止的失控小爬虫
- 成型的商业对手
- 抽风的搜索引擎
定义
- 爬虫 : 使用任何技术手段, 批量获取网站信息的一种方式。
- 反爬虫 : 使用任何技术手段, 阻止别人批量获取自己网站信息的一种方式。
- 误伤 : 在反爬虫的过程中, 错误的将普通用户识别为爬虫。
- 拦截 : 成功地阻止爬虫访问。
- 资源 : 机器成本与人力成本的总和。
知己知彼: 如何编写简单爬虫
- 分析页面请求格式
- 创建合适的http请求
- 批量发送http请求, 获取数据
知己知彼: 如何编写高级爬虫
- 分布式(我们只是为了防止封IP而已, 不要多想)
- 模拟JavaScript
- PhantomJs
优缺点
- 越是低级的爬虫,越容易被封锁, 但是性能好, 成本低。
- 越是高级的爬虫, 越难被封锁, 但是性能低, 成本也越高。
- 当成本高到一定程度, 我们就可以无需再对爬虫进行封锁。
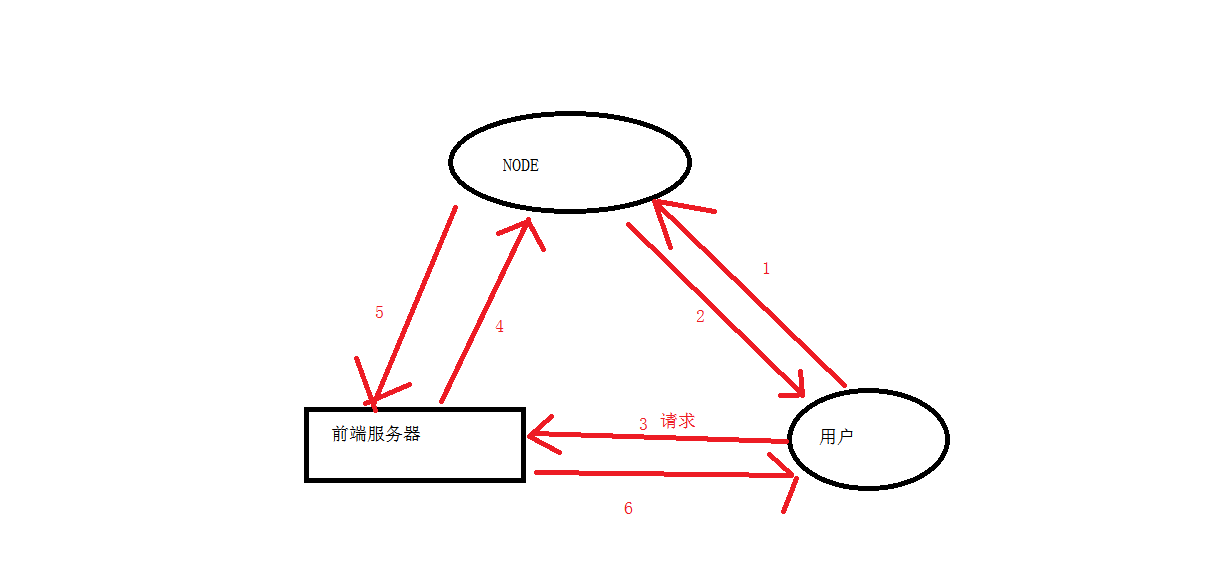
如何设计一个反爬虫系统(常规架构)
- 对请求进行预处理, 便于识别
- 识别是否是爬虫
- 针对识别结果, 进行适当的处理。
上一页是逗你玩的
- 如果能识别出爬虫, 哪还有那么多废话?想怎么搞它就怎么搞它
- 如果识别不出来爬虫, 你对谁做适当处理?
- 三句话里面有两句是废话, 只有一句有用的。 而且还没给出具体实施方式。
- 这种架构(师)有什么用?
传统反爬虫手段
- 后台对访问进行统计, 如果单个IP访问超过阈值, 予以封锁。
- 后台对访问进行统计, 如果单个session访问超过阈值, 予以封锁。
- 后台对访问进行统计, 如果单个userAgent访问超过阈值, 予以封锁。
- 以上的组合
- 效果均一般, 所以还是用JavaScript比较靠谱⬇️
纯JavaScript反爬虫demo
- 更改连接地址
纯JavaScript反爬虫demo
- 更改key
纯JavaScript反爬虫demo
- 更改动态key
纯JavaScript反爬虫demo
- 十分复杂的更改key
浏览器检测
- 检测IE 的bug
- 检测FF的严格
- 检测Chrome的强大特性
我抓到你了——然后该怎么办
- 不会引发生产事件——直接拦截
- 可能引发生产事件——给假数据(也叫投毒)
技术压制
- DotA AI: de命令
- 当AI被击杀后, 它获取经验的倍数会提升。
- 因此, 前期杀AI太多, AI会一身神装, 无法击杀。
- 正确的做法是, 压制对方等级, 但是不击杀。
心理战
- 挑衅
- 怜悯
- 嘲讽
- 猥琐
- ⬇️

放水
- 程序员都不容易
- 做爬虫的尤其不容易
- 可怜可怜他们给他们一小口饭吃吧。 没准过几天你就因为反爬虫做得好, 改行做爬虫了